RCore-三叶虫
最近在准备 OS 内核赛,需要熟悉下 rust + OS 的技术栈
背景知识
只是查漏补缺以及一些感兴趣的知识
运行环境
Rust编译器通过 目标三元组 (Target Triplet) 来描述一个软件运行的目标平台。它一般包括 CPU、操作系统和运行时库等信息,从而控制Rust编译器可执行代码生成。这里我们选择 riscv64gc-unknown-none-elf 目标平台。这其中的 CPU 架构是 riscv64gc ,CPU厂商是 unknown ,操作系统是 none , elf 表示没有标准的运行时库(表明没有任何系统调用的封装支持),但可以生成 ELF 格式的执行程序。
函数调用
其他控制流都只需要跳转到一个 编译期固定下来 的地址,而函数调用的返回跳转是跳转到一个 运行时确定 (确切地说是在函数调用发生的时候)的地址。
总结一下,在进行函数调用的时候,我们通过 jalr 指令保存返回地址并实现跳转;而在函数即将返回的时候,则通过 ret 伪指令回到跳转之前的下一条指令继续执行。这样,RISC-V 的这两条指令就实现了函数调用流程的核心机制。
我们是在 ra 寄存器中保存返回地址的。如果在函数中没有调用其他函数,那 ra 的值不会变化,函数调用流程能够正常工作。但遗憾的是,在实际编写代码的时候我们常常会遇到函数 多层嵌套调用 的情形。
若想正确实现嵌套函数调用的控制流,我们必须通过某种方式保证:在一个函数调用子函数的前后,ra 寄存器的值不能发生变化。但实际上,这并不仅仅局限于 ra 一个寄存器,而是作用于所有的通用寄存器。我们将由于函数调用,在控制流转移前后需要保持不变的寄存器集合称之为 函数调用上下文 (Function Call Context) 。
我们若想在子函数调用前后保持函数调用上下文不变,就需要物理内存的帮助。确切的说,在调用子函数之前,我们需要在物理内存中的一个区域 保存 (Save) 函数调用上下文中的寄存器;而在函数执行完毕后,我们会从内存中同样的区域读取并 恢复 (Restore) 函数调用上下文中的寄存器。实际上,这一工作是由子函数的调用者和被调用者(也就是子函数自身)合作完成。
被调用者保存(Callee-Saved) 寄存器 :被调用的函数可能会覆盖这些寄存器,需要被调用的函数来保存的寄存器,即由被调用的函数来保证在调用前后,这些寄存器保持不变;
调用者保存(Caller-Saved) 寄存器 :被调用的函数可能会覆盖这些寄存器,需要发起调用的函数来保存的寄存器,即由发起调用的函数来保证在调用前后,这些寄存器保持不变。
调用规范 (Calling Convention) 约定在某个指令集架构上,某种编程语言的函数调用如何实现。它包括了以下内容:
函数的输入参数和返回值如何传递;
函数调用上下文中调用者/被调用者保存寄存器的划分;
其他的在函数调用流程中对于寄存器的使用方法。
调用规范是对于一种确定的编程语言来说的,因为一般意义上的函数调用只会在编程语言的内部进行。当一种语言想要调用用另一门编程语言编写的函数接口时,编译器就需要同时清楚两门语言的调用规范,并对寄存器的使用做出调整。
sp 寄存器常用来保存 栈指针 (Stack Pointer),它指向内存中栈顶地址。在 RISC-V 架构中,栈是从高地址向低地址增长的。在一个函数中,作为起始的开场代码负责分配一块新的栈空间,即将 sp 的值减小相应的字节数即可。对应的物理内存的一部分便可以被这个函数用来进行函数调用上下文的保存/恢复,这块物理内存被称为这个函数的 栈帧 (Stack Frame)。同理,函数中的结尾代码负责将开场代码分配的栈帧回收,这也仅仅需要将 sp 的值增加相同的字节数回到分配之前的状态。这也可以解释为什么 sp 是一个被调用者保存寄存器。
SBI
我们编写的 OS 内核位于 Supervisor 特权级,而 RustSBI 位于 Machine 特权级,也是最高的特权级。类似 RustSBI 这样运行在 Machine 特权级的软件被称为 Supervisor Execution Environment(SEE),即 Supervisor 执行环境。两层软件之间的接口被称为 Supervisor Binary Interface(SBI),即 Supervisor 二进制接口。
动手实现
先按照指导书的讲解一步步搭建,至于编程题以及实验,似乎延迟完成会更好,评论区有抱怨:花很多时间完成的任务在下一章的指导书上给出了。
项目全览
1 | |
三叶虫操作系统的功能十分简单:将程序加载到正确的位置,支持简单的输出。
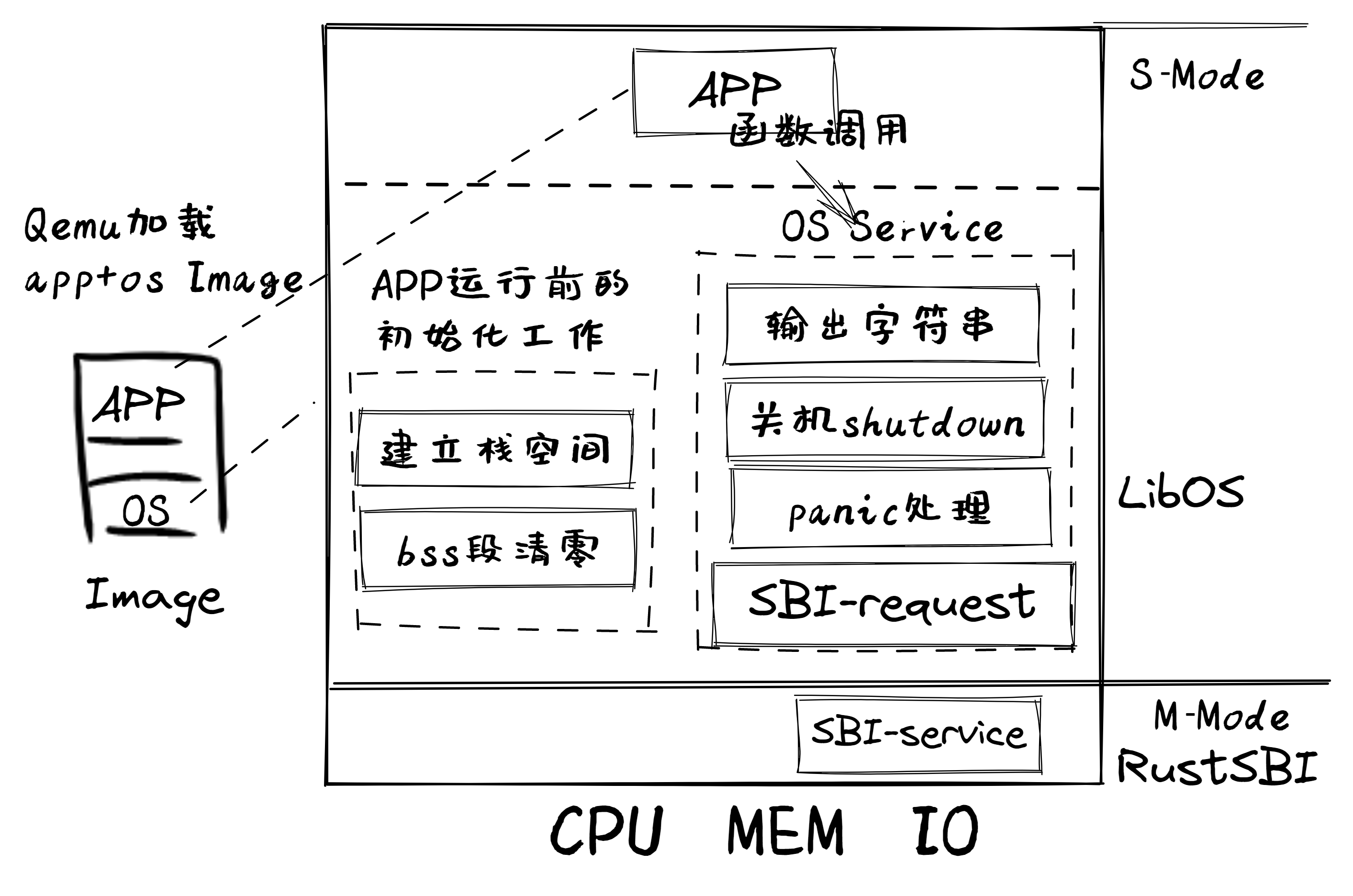
代码介绍
启动流程
在Qemu模拟的 virt 硬件平台上,物理内存的起始物理地址为 0x80000000 ,物理内存的默认大小为 128MiB ,它可以通过 -m 选项进行配置。如果使用默认配置的 128MiB 物理内存则对应的物理地址区间为 [0x80000000,0x88000000) 。
我们目前的启动命令如下:
1 | |
qemu启动后,把作为 bootloader 的 rustsbi-qemu.bin加载到物理内存以物理地址 0x80000000 开头的区域上,同时把内核镜像 os.bin 加载到以物理地址 0x80200000 开头的区域上。
Qemu 模拟的启动流程则可以分为三个阶段:第一个阶段由固化在 Qemu 内的一小段汇编程序负责;第二个阶段由 bootloader 负责;第三个阶段则由内核镜像负责。
第一阶段:将必要的文件载入到 Qemu 物理内存之后,Qemu CPU 的程序计数器(PC, Program Counter)会被初始化为
0x1000,因此 Qemu 实际执行的第一条指令位于物理地址0x1000,接下来它将执行寥寥数条指令并跳转到物理地址0x80000000对应的指令处并进入第二阶段。从后面的调试过程可以看出,该地址0x80000000被固化在 Qemu 中,作为 Qemu 的使用者,我们在不触及 Qemu 源代码的情况下无法进行更改。第二阶段:由于 Qemu 的第一阶段固定跳转到
0x80000000,我们需要将负责第二阶段的 bootloaderrustsbi-qemu.bin放在以物理地址0x80000000开头的物理内存中,这样就能保证0x80000000处正好保存 bootloader 的第一条指令。在这一阶段,bootloader 负责对计算机进行一些初始化工作,并跳转到下一阶段软件的入口,在 Qemu 上即可实现将计算机控制权移交给我们的内核镜像os.bin。这里需要注意的是,对于不同的 bootloader 而言,下一阶段软件的入口不一定相同,而且获取这一信息的方式和时间点也不同:入口地址可能是一个预先约定好的固定的值,也有可能是在 bootloader 运行期间才动态获取到的值。我们选用的 RustSBI 则是将下一阶段的入口地址预先约定为固定的0x80200000,在 RustSBI 的初始化工作完成之后,它会跳转到该地址并将计算机控制权移交给下一阶段的软件——也即我们的内核镜像。第三阶段:为了正确地和上一阶段的 RustSBI 对接,我们需要保证内核的第一条指令位于物理地址
0x80200000处。为此,我们需要将内核镜像预先加载到 Qemu 物理内存以地址0x80200000开头的区域上。一旦 CPU 开始执行内核的第一条指令,证明计算机的控制权已经被移交给我们的内核,也就达到了本节的目标。
那么如何保证我们内核的入口恰好在可执行文件os.bin的开头呢?先来看链接的脚本linker.ld :(链接脚本可以用来安排链接多个文件时数据的排布,即规定怎么合并)
1 | |
现在我们已经可以实现,在qemu启动后,到达的0x80200000处,是我们设定的_start。接着,我们希望在程序开始前,可以先分配好栈空间之类的,否则直接进入main函数,当我们试图调用函数时,不知道会发生什么。所以我们需要在_start处,先进行一些操作。我们通过嵌入汇编entry.asm来实现。
1 | |
可以看到,我们在内核的内存布局中预留了一块大小为4096x16字节的空间用作接下来要运行的程序的栈空间。在 RISC-V 架构上,栈是从高地址向低地址增长。因此,最开始的时候栈为空,栈顶(top)和栈底(buttom)位于相同的位置,我们用更高地址的符号 boot_stack_top 来标识栈顶的位置。同时,我们用更低地址的符号 boot_stack_lower_bound 来标识栈顶能够增长到的下限位置,它们都被设置为全局符号供其他目标文件使用。
我们将这块空间放置在一个名为 .bss.stack 的段中,在链接脚本 linker.ld 中可以看到 .bss.stack 段最终会被汇集到 .bss 段中。内存布局为:
(地址从小到大).bss | lower_bound | space | bottom(stack_top/top)
在程序运行时,stack_top会向lower_bound增长。
除了分配栈空间,我们还让sp寄存器(一般用来保存栈指针)保存了栈顶位置,接着调用我们的main函数rust_main。
因为三叶虫的逻辑很简单,剩下的部分通过讲解功能,顺便熟悉rust的语法。
串口输出
由于我们是在裸机上运行程序,没有标准库等运行时环境对于输出的支持,我们需要用sbi的API来实现。