#proj #os #rust
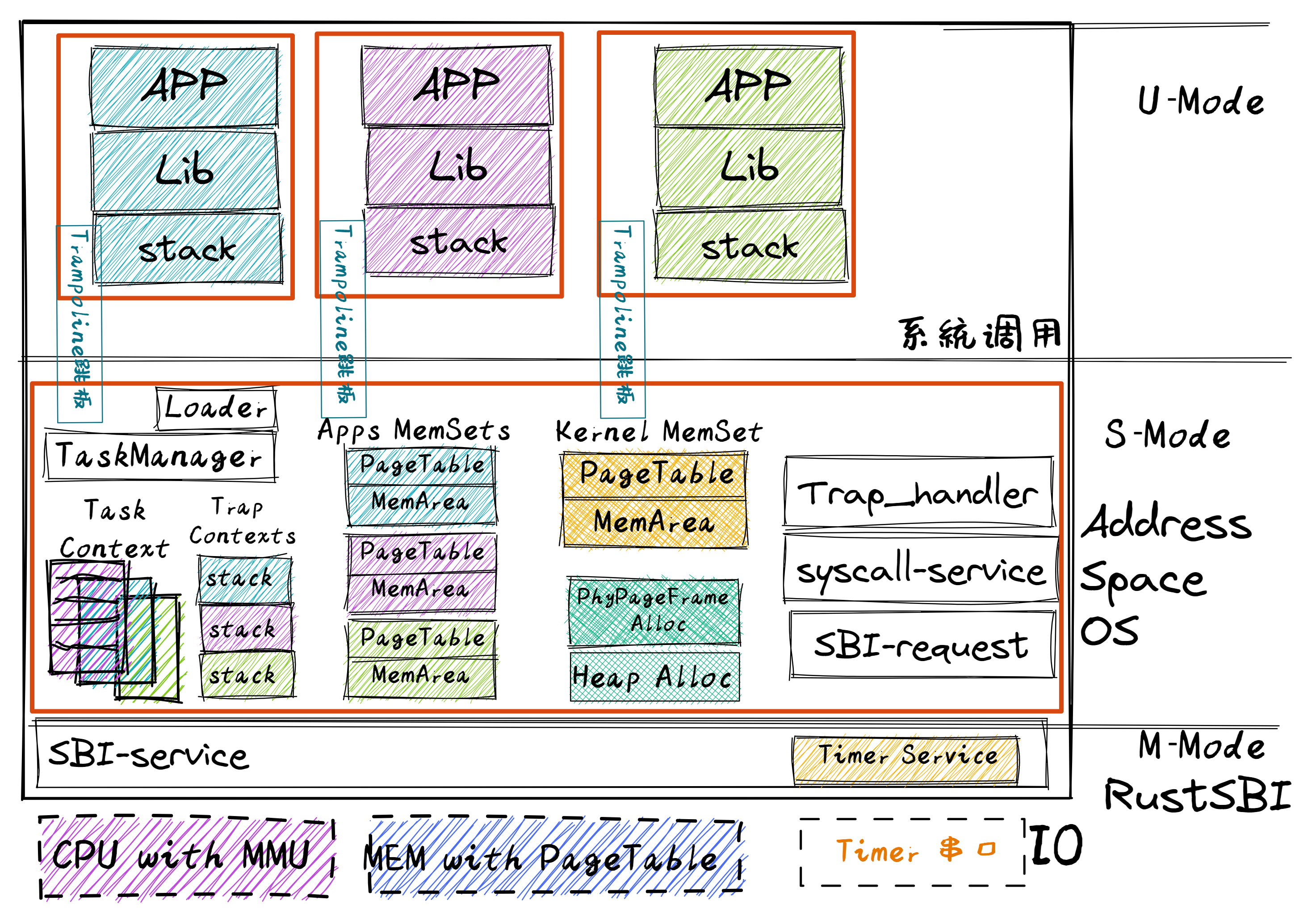
总体结构
开发思路 这章的代码量剧增,需要记录一下代码添加的思路。
改进应用程序:使用虚拟地址
加入动态分配内存的功能heap_allocator.rs
地址转换address.rs
建立页表page_table.rs
背景知识 rust 静态分配 这个变量可能是一个局部变量,它来自于正在执行的当前函数调用栈上,即它是被分配在栈上;这个变量也可能是一个全局变量,它一般被分配在数据段中。它们有一个共同点:在编译器编译程序时已经知道这些变量所占的字节大小,于是给它们分配一块固定的内存将它们存储其中,这样变量在栈帧/数据段中的位置就被固定了下来。
动态分配 除了可以灵活利用内存之外,动态分配还允许我们以尽可能小的代价灵活调整变量的生命周期。动态分配允许我们构造另一种并不一直存在也不绑定于函数调用的变量生命周期:以 C 语言为例,可以说自 malloc 拿到指向一个变量的指针到 free 将它回收之前的这段时间,这个变量在堆上存在。由于需要跨越函数调用,我们需要作为堆上数据代表的变量在函数间以参数或返回值的形式进行传递,而这些变量一般都很小(如一个指针),其拷贝开销可以忽略。
rust 的堆数据结构
裸指针 *const T/*mut T 基本等价于 C/C++ 里面的普通指针 T*,编译器只能对它进行最基本的可变性检查(只读的数据不能写),通过裸指针解引用来访问数据的行为是 unsafe 行为,需要被包裹在 unsafe 块中。
引用 &T/&mut T 实质上只是一个地址范围
智能指针不仅包含它指向区域的地址范围,还含有一些额外的信息。
软件控制映射 内存虚拟化
管理页表 操作系统需要负责管理:
物理页:管理其分配和回收
多级页表:以节点为单位进行管理的,需要维护好各个映射关系
逻辑段 所谓逻辑段,就是指地址区间中的一段实际可用(即 MMU 通过查多级页表可以正确完成地址转换)的地址连续的虚拟地址区间,该区间内包含的所有虚拟页面都以一种相同的方式映射到物理页帧,具有可读/可写/可执行等属性。
地址空间 地址空间 是一系列有关联的不一定连续的逻辑段,这种关联一般是指这些逻辑段组成的虚拟内存空间与一个运行的程序(目前把一个运行的程序称为任务,后续会称为进程)绑定,即这个运行的程序对代码和数据的直接访问范围限制在它关联的虚拟地址空间之内。这样我们就有任务的地址空间,内核的地址空间等说法了。
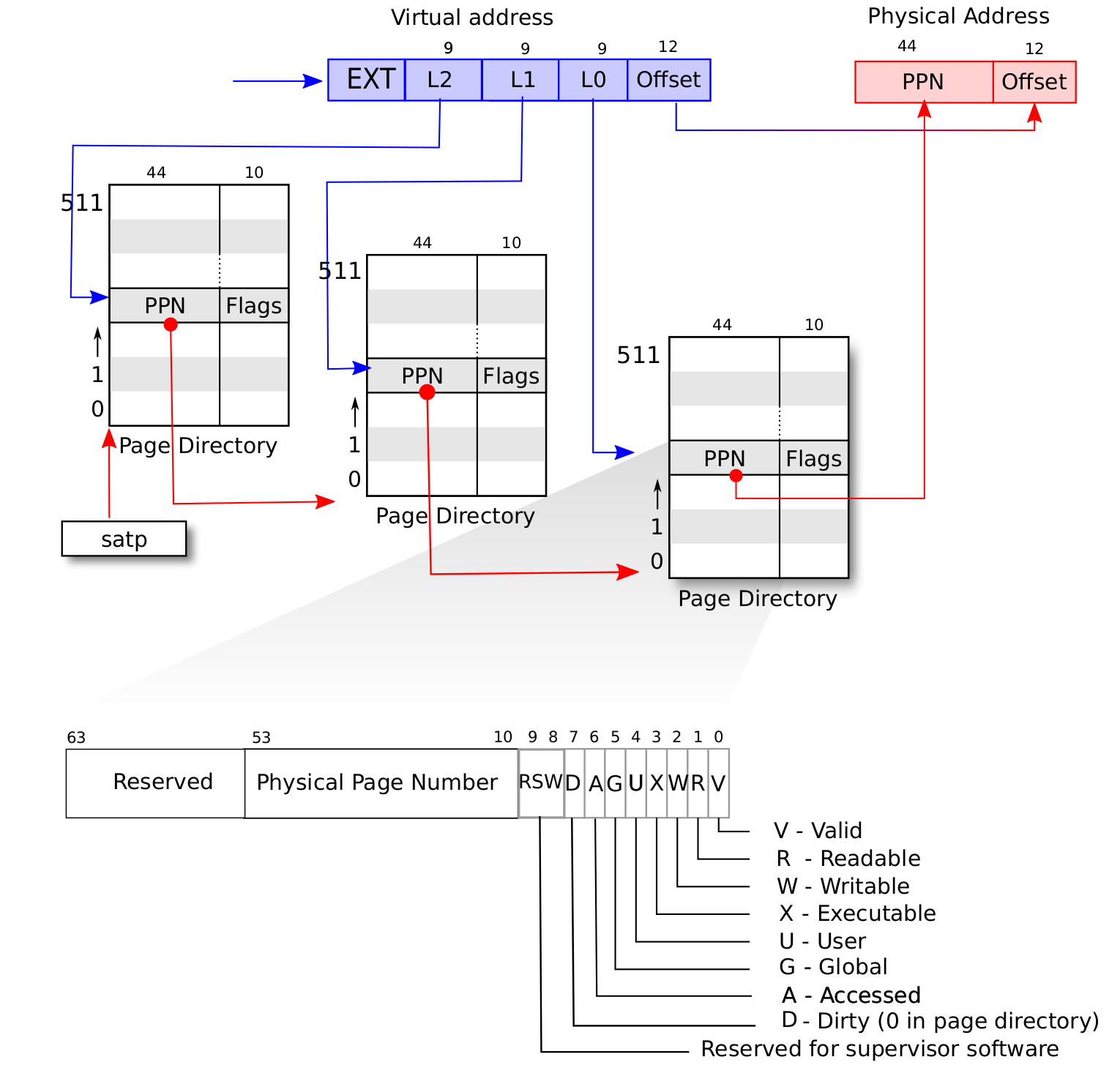
硬件支持转换 内存控制寄存器 默认情况下 MMU 未被使能(启用),此时无论 CPU 位于哪个特权级,访存的地址都会作为一个物理地址交给对应的内存控制单元来直接访问物理内存。我们可以通过修改 S 特权级的一个名为 satp 的 CSR 来启用分页模式,在这之后 S 和 U 特权级的访存地址会被视为一个虚拟地址,它需要经过 MMU 的地址转换变为一个物理地址,再通过它来访问物理内存;而 M 特权级的访存地址,我们可设定是内存的物理地址。
以下为satp的字段分布:
MODE 控制 CPU 使用哪种页表实现; ASID 表示地址空间标识符,这里还没有涉及到进程的概念,我们不需要管这个地方;PPN 存的是根页表所在的物理页号。这样,给定一个虚拟页号,CPU 就可以从三级页表的根页表开始一步步的将其映射到一个物理页号。
当 MODE 设置为 0 的时候,代表所有访存都被视为物理地址;而设置为 8 的时候,SV39 分页机制被启用,所有 S/U 特权级的访存被视为一个 39 位的虚拟地址,它们需要先经过 MMU 的地址转换流程,如果顺利的话,则会变成一个 56 位的物理地址来访问物理内存;否则则会触发异常,这体现了分页机制的内存保护能力。
SV39地址转换
TLB 如果修改了 satp 寄存器,说明内核切换到了一个与先前映射方式完全不同的页表。此时快表里面存储的映射已经失效了,这种情况下内核要在修改 satp 的指令后面马上使用 sfence.vma 指令刷新清空整个 TLB。
同样,我们手动修改一个页表项之后,也修改了映射,但 TLB 并不会自动刷新清空,我们也需要使用 sfence.vma 指令刷新整个 TLB。注:可以在 sfence.vma 指令后面加上一个虚拟地址,这样 sfence.vma只会刷新TLB中关于这个虚拟地址的单个映射项。
综述 对于虚实的转换,我觉得可以这样概括:
软件负责维护映射(页表、地址空间)
硬件负责真实转换(MMU查表、TLB缓存)
具体实现 动态分配 关注heap_allocator.rs:
1 2 3 4 5 6 7 8 9 10 11 12 13 use crate::config::KERNEL_HEAP_SIZE;use buddy_system_allocator::LockedHeap;#[global_allocator] static HEAP_ALLOCATOR: LockedHeap = LockedHeap::empty ();#[alloc_error_handler] pub fn handle_alloc_error (layout: core::alloc::Layout) -> ! {panic! ("Heap allocation error, layout = {:?}" , layout);
#[global_allocator] 是一个属性宏,它用来指定全局分配器。在 Rust 中,默认情况下会使用系统的堆分配器(如 alloc::alloc),但是可以通过该属性替换为自定义的分配器。我们这里使用 buddy system allocator。
#[alloc_error_handler] 是一个属性宏,用来标记堆分配错误的处理函数。此函数在发生堆分配错误(例如 Vec 扩展时分配失败)时被调用。它接收一个 core::alloc::Layout 类型的参数,表示分配请求的布局信息(例如请求的内存大小和对齐方式)。使用 panic! 宏打印错误信息,并且直接调用 panic! 使程序进入恐慌状态。! 表示函数不会返回,它会导致程序终止或进入错误处理流程。
1 2 3 4 5 6 7 8 9 10 11 static mut HEAP_SPACE: [u8 ; KERNEL_HEAP_SIZE] = [0 ; KERNEL_HEAP_SIZE];pub fn init_heap () {unsafe {lock ()init (HEAP_SPACE.as_ptr () as usize , KERNEL_HEAP_SIZE);
可以看到堆的空间是静态的,是我们分配系统为 OS 提供了动态分配的功能。
操作物理空间 相关的实现在frame_allocator.rs中,这部分负责管理物理内存 。
FrameTracker:一个 RAII 对象(该对象与其绑定的 PPN 生命周期应该相同),记录了其跟踪的 PPN,以及可以用于操作该 PPN。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 pub struct FrameTracker {pub ppn: PhysPageNum,impl FrameTracker {pub fn new (ppn: PhysPageNum) -> Self {let bytes_array = ppn.get_bytes_array ();for i in bytes_array {0 ;Self { ppn }impl Drop for FrameTracker {fn drop (&mut self ) {frame_dealloc (self .ppn);
StackFrameAllocator:用于管理物理地址空间。使用传入的两个参数,代表物理空间的范围,用于初始化。current是空闲物理空间开始地址,end 是该空闲区的结束地址。recycled用于存放使用过但已经释放的 ppn (可以看到这里用到了之前堆的结构)
其中的FrameAllocator是一组方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 pub struct StackFrameAllocator {usize ,usize ,Vec <usize >,impl StackFrameAllocator {pub fn init (&mut self , l: PhysPageNum, r: PhysPageNum) {self .current = l.0 ;self .end = r.0 ;impl FrameAllocator for StackFrameAllocator {fn new () -> Self {Self {0 ,0 ,Vec ::new (),fn alloc (&mut self ) -> Option <PhysPageNum> {if let Some (ppn) = self .recycled.pop () {Some (ppn.into ())else if self .current == self .end {None else {self .current += 1 ;Some ((self .current - 1 ).into ())fn dealloc (&mut self , ppn: PhysPageNum) {let ppn = ppn.0 ;if ppn >= self .current || self .recycled.iter ().any (|&v| v == ppn) {panic! ("Frame ppn={:#x} has not been allocated!" , ppn);self .recycled.push (ppn);
我们同时需要向外提供 StackFrameAllocator的使用接口:提供给 FrameTracker使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 type FrameAllocatorImpl = StackFrameAllocator;pub static ref FRAME_ALLOCATOR: UPSafeCell<FrameAllocatorImpl> =unsafe { UPSafeCell::new (FrameAllocatorImpl::new ()) };pub fn init_frame_allocator () {extern "C" {fn ekernel ();exclusive_access ().init (from (ekernel as usize ).ceil (),from (MEMORY_END).floor (),pub fn frame_alloc () -> Option <FrameTracker> {exclusive_access ()alloc ()map (FrameTracker::new)fn frame_dealloc (ppn: PhysPageNum) {exclusive_access ().dealloc (ppn);
我们创建了一个全局变量FRAME_ALLOCATOR
这部分代码实际上为外部提供了3个函数:
init_frame_allocator:使用 ekernel 和 内存结束地址 初始化物理内存分配器
ekernel 在 linker-qemu.ld中可以找到,但前面的部分,存疑
frame_alloc:内存分配器通过自己的信息,找到未被使用的或者已经被丢弃物理页,初始化并包装成FrameTracker返回frame_dealloc:内存分配器检查该 PPN 是否合法,接着放入回收区。实际上,我们不会在外部调用这个函数:FrameTracker为 RAII 对象,使用者在通过frame_alloc获得它后,负责维持其“生命”,当其生命周期结束时,会自动在其drop的方法中,调用frame_dealloc
页表 内存计算 SV39 分页机制等价于一颗字典树.
我们可以手动算出页表占用的内存大小:(页表中每个节点都要占用 4kb)
三级节点:512 * 4 Kb = 2Mb
二级节点:512 ^2 * 4Kb = 1Gb
可以计算出映射连续的 T 字节空间需要的页表占用的内存为:
PPN & VPN address.rs集中了 PPN、VPN 的方法的实现、以及一个很棒的设计:VPNRange
其中包含了四种类型:
PhysAddrVirtAddrPhysPageNumVirtPageNum
都实现了:
和 raw number(usize)相互转换的方法
Num和Addr的转化。给两个 addr 类实现了 floor、ceil、page_offset aligned方法,用于对齐页的地址
1 2 3 4 5 6 7 8 9 impl From <VirtAddr> for usize {fn from (v: VirtAddr) -> Self {if v.0 >= (1 << (VA_WIDTH_SV39 - 1 )) {0 | (!((1 << VA_WIDTH_SV39) - 1 ))else {0
这个函数实现从 VirtAddr 到 usize 的转换,存疑。当 vaddr 超过 VA_WIDTH_SV39的位宽时,保留超过的位,并将位宽内清0,否则保留。
1 2 3 4 5 6 7 8 9 10 11 impl VirtPageNum {pub fn indexes (&self ) -> [usize ; 3 ] {let mut vpn = self .0 ;let mut idx = [0usize ; 3 ];for i in (0 ..3 ).rev () {511 ;9 ;
我们用这个方法提取 VPN 的 index:即其在三级页表中,各个页表中的索引。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 impl PhysPageNum {pub fn get_pte_array (&self ) -> &'static mut [PageTableEntry] {let pa : PhysAddr = (*self ).into ();unsafe { core::slice::from_raw_parts_mut (pa.0 as *mut PageTableEntry, 512 ) }pub fn get_bytes_array (&self ) -> &'static mut [u8 ] {let pa : PhysAddr = (*self ).into ();unsafe { core::slice::from_raw_parts_mut (pa.0 as *mut u8 , 4096 ) }pub fn get_mut <T>(&self ) -> &'static mut T {let pa : PhysAddr = (*self ).into ();unsafe { (pa.0 as *mut T).as_mut ().unwrap () }
用这些方法可以将一个物理页看作:
一个页表节点
bytes 数组
或者得到该页的可变引用:注意'static mut 生命周期意味着你返回的引用在整个程序生命周期内都有效
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 pub struct SimpleRange <T>where Copy + PartialEq + PartialOrd + Debug ,impl <T> SimpleRange<T>where Copy + PartialEq + PartialOrd + Debug ,pub fn new (start: T, end: T) -> Self {assert! (start <= end, "start {:?} > end {:?}!" , start, end);Self { l: start, r: end }pub fn get_start (&self ) -> T {self .lpub fn get_end (&self ) -> T {self .rimpl <T> IntoIterator for SimpleRange <T>where Copy + PartialEq + PartialOrd + Debug ,type Item = T;type IntoIter = SimpleRangeIterator<T>;fn into_iter (self ) -> Self ::IntoIter {new (self .l, self .r)
SimpleRange:StepByOne、Copy、PartialEq、PartialOrd 和 Debug trait。
最后是 SimpleRangeIterator和SimpleRange 的转换方法
SimpleRangeIterator:SimpleRange中迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 pub struct SimpleRangeIterator <T>where Copy + PartialEq + PartialOrd + Debug ,impl <T> SimpleRangeIterator<T>where Copy + PartialEq + PartialOrd + Debug ,pub fn new (l: T, r: T) -> Self {Self { current: l, end: r }impl <T> Iterator for SimpleRangeIterator <T>where Copy + PartialEq + PartialOrd + Debug ,type Item = T;fn next (&mut self ) -> Option <Self ::Item> {if self .current == self .end {None else {let t = self .current;self .current.step ();Some (t)pub type VPNRange = SimpleRange<VirtPageNum>;
我们目前只给 VirtPageNum实现了迭代器加一的操作:
1 2 3 4 5 6 7 8 pub trait StepByOne {fn step (&mut self );impl StepByOne for VirtPageNum {fn step (&mut self ) {self .0 += 1 ;
总的来说,address.rs提供很多对 PPN、VPN的快速操作,供我们在其他代码中使用。
页表机制 可以在page_table.rs中找到关于页表的设计:
1 2 3 4 5 pub struct PageTable {Vec <FrameTracker>,
我们记录了页表的基地址。frames代表了目前页表已经映射的物理页、以及页表节点的物理页。我们接着一个个分析其方法:
1 2 3 4 5 6 7 8 9 impl PageTable {pub fn new () -> Self {let frame = frame_alloc ().unwrap ();vec! [frame],
新建一个页表:获取物理页、设置根节点、将该物理页放入frames(这就是在 frame_allocator.rs 中,我提到的:使用者会负责维持其生命周期 )
1 2 3 4 5 6 7 pub fn from_token (satp: usize ) -> Self {Self {from (satp & ((1usize << 44 ) - 1 )),Vec ::new (),
这个算是一个 helper 类函数,from_token 可以临时创建一个专用来手动查页表的 PageTable ,它仅有一个从传入的 satp token 中得到的多级页表根节点的物理页号,它的 frames 字段为空,也即不实际控制任何资源;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 fn find_pte_create (&mut self , vpn: VirtPageNum) -> Option <&mut PageTableEntry> {let idxs = vpn.indexes ();let mut ppn = self .root_ppn;let mut result : Option <&mut PageTableEntry> = None ;for (i, idx) in idxs.iter ().enumerate () {let pte = &mut ppn.get_pte_array ()[*idx];if i == 2 {Some (pte);break ;if !pte.is_valid () {let frame = frame_alloc ().unwrap ();new (frame.ppn, PTEFlags::V);self .frames.push (frame);ppn ();fn find_pte (&self , vpn: VirtPageNum) -> Option <&mut PageTableEntry> {let idxs = vpn.indexes ();let mut ppn = self .root_ppn;let mut result : Option <&mut PageTableEntry> = None ;for (i, idx) in idxs.iter ().enumerate () {let pte = &mut ppn.get_pte_array ()[*idx];if i == 2 {Some (pte);break ;if !pte.is_valid () {return None ;ppn ();
这两个方法都是负责根据 VPN 寻找 PTE,只不过一个在遍历的过程中发现有节点尚未创建则会新建一个节点(见!pte.is_valid()的处理)。i代表页表的级,idx则代表目前所在的索引。
注意在更新页表项的时候,不仅要更新物理页号,还要将标志位 V 置 1,不然硬件在查多级页表的时候,会认为这个页表项不合法,从而触发 Page Fault 而不能向下走。
两者返回的都是 PTE 的可变引用。
1 2 3 4 5 6 7 8 9 10 11 12 #[allow(unused)] pub fn map (&mut self , vpn: VirtPageNum, ppn: PhysPageNum, flags: PTEFlags) {let pte = self .find_pte_create (vpn).unwrap ();assert! (!pte.is_valid (), "vpn {:?} is mapped before mapping" , vpn);new (ppn, flags | PTEFlags::V);#[allow(unused)] pub fn unmap (&mut self , vpn: VirtPageNum) {let pte = self .find_pte (vpn).unwrap ();assert! (pte.is_valid (), "vpn {:?} is invalid before unmapping" , vpn);empty ();
接下来是页表项的映射。对于map:注意我们的find_pte_create
1 2 3 4 5 6 pub fn translate (&self , vpn: VirtPageNum) -> Option <PageTableEntry> {self .find_pte (vpn).map (|pte| *pte)pub fn token (&self ) -> usize {8usize << 60 | self .root_ppn.0
translate 调用 find_pte 来实现,如果能够找到页表项,那么它会将页表项拷贝一份并返回,否则就返回一个 None 。之后,当遇到需要查一个特定页表(非当前正处在的地址空间的页表时),便可先通过 PageTable::from_token 新建一个页表,再调用它的 translate 方法查页表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 pub fn translated_byte_buffer (token: usize , ptr: *const u8 , len: usize ) -> Vec <&'static mut [u8 ]> {let page_table = PageTable::from_token (token);let mut start = ptr as usize ;let end = start + len;let mut v = Vec ::new ();while start < end {let start_va = VirtAddr::from (start);let mut vpn = start_va.floor ();let ppn = page_table.translate (vpn).unwrap ().ppn ();step ();let mut end_va : VirtAddr = vpn.into ();min (VirtAddr::from (end));if end_va.page_offset () == 0 {push (&mut ppn.get_bytes_array ()[start_va.page_offset ()..]);else {push (&mut ppn.get_bytes_array ()[start_va.page_offset ()..end_va.page_offset ()]);into ();
这个函数使得内核可以访问用户空间的数据:通过解析用户的页表,构造出目标地址范围内 字节序列的 slice 的引用。
地址空间 逻辑段 1 2 3 4 5 6 7 pub struct MapArea {
基本的结构,包含了:
映射的虚拟地址的范围
虚拟页和物理页帧的映射(也利用了 FrameTracker RAII 的特性,以此来维持其生命周期)
恒等映射还是正常映射
该逻辑段的权限 U/R/W/X
还有一些映射/解映射的方法,利用 VPNRange的迭代方法可以很优雅地完成。
地址空间 1 2 3 4 pub struct MemorySet {Vec <MapArea>,
基本结构:
以下为其方法:
1 2 3 4 5 6 7 8 fn push (&mut self , mut map_area: MapArea, data: Option <&[u8 ]>) {map (&mut self .page_table);if let Some (data) = data {copy_data (&self .page_table, data);self .areas.push (map_area);
我们通过指定的页表,完成对指定的逻辑段map_area的映射,有可能还需要复制数据(读取)。接着放入逻辑段集合areas。
1 2 3 4 5 6 7 8 9 10 11 12 pub fn insert_framed_area (mut self ,self .push (new (start_va, end_va, MapType::Framed, permission),None ,
通过调用push,优雅地映射、放入逻辑段。但似乎是提供给外部使用的(?。MemorySet内部都用更细致的 push
1 2 3 4 5 6 7 8 fn map_trampoline (&mut self ) {self .page_table.map (from (TRAMPOLINE).into (),from (strampoline as usize ).into (),
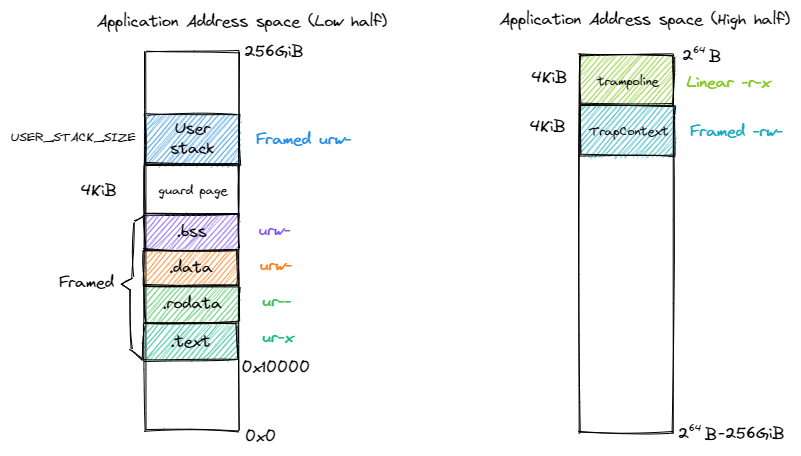
用户空间 和 内核空间都需要用到 跳板 机制。
在开启分页模式之后,内核和应用代码都只能看到各自的虚拟地址空间,而在它们的视角中,这段汇编代码都被放在它们各自地址空间的最高虚拟页面上,由于这段汇编代码在执行的时候涉及到地址空间切换,故而被称为跳板页面。
在产生trap前后的一小段时间内会有一个比较 极端 的情况,即刚产生trap时,CPU已经进入了内核态(即Supervisor Mode),但此时执行代码和访问数据还是在应用程序所处的用户态虚拟地址空间中,而不是我们通常理解的内核虚拟地址空间。在这段特殊的时间内,CPU指令为什么能够被连续执行呢?这里需要注意:无论是内核还是应用的地址空间,跳板的虚拟页均位于同样位置,且它们也将会映射到同一个实际存放这段汇编代码的物理页帧。也就是说,在执行 __alltraps 或 __restore 函数进行地址空间切换的时候,应用的用户态虚拟地址空间和操作系统内核的内核态虚拟地址空间对切换地址空间的指令所在页的映射方式均是相同的,这就说明了这段切换地址空间的指令控制流仍是可以连续执行的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # in trap.S
内核
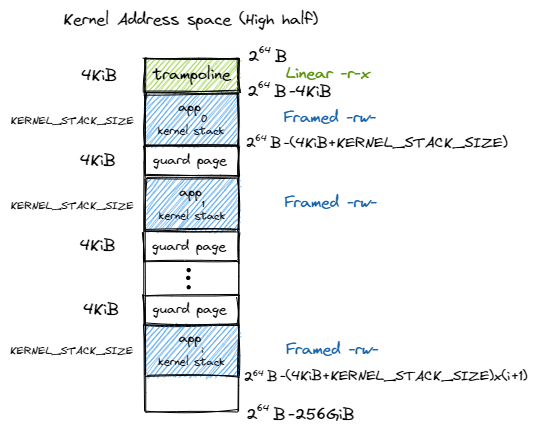
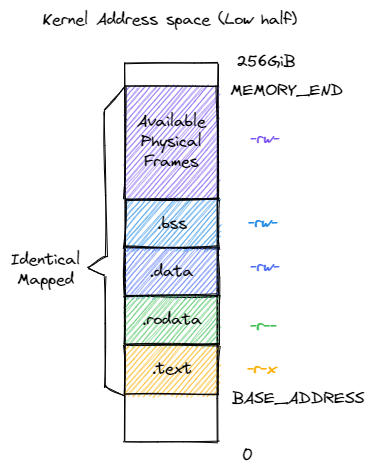
我们会将所有应用的内核栈放在一起。、只利用高 256gb 和低 256gb,是硬件要求。
内核的四个逻辑段 .text/.rodata/.data/.bss 被恒等映射到物理内存,这使得我们在无需调整内核内存布局 os/src/linker.ld 的情况下就仍能象启用页表机制之前那样访问内核的各个段。
按照这个布局,可以写出创建内核地址空间的方法new_kernel:
map_trampoline从汇编文件中得到其他段的符号地址
根据地址、权限等构造逻辑段,并push进空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 pub fn new_kernel () -> Self {let mut memory_set = Self ::new_bare ();map_trampoline ();println! (".text [{:#x}, {:#x})" , stext as usize , etext as usize );println! (".rodata [{:#x}, {:#x})" , srodata as usize , erodata as usize );println! (".data [{:#x}, {:#x})" , sdata as usize , edata as usize );println! (".bss [{:#x}, {:#x})" ,as usize , ebss as usize println! ("mapping .text section" );push (new (as usize ).into (),as usize ).into (),None ,println! ("mapping .rodata section" );push (new (as usize ).into (),as usize ).into (),None ,println! ("mapping .data section" );push (new (as usize ).into (),as usize ).into (),None ,println! ("mapping .bss section" );push (new (as usize ).into (),as usize ).into (),None ,println! ("mapping physical memory" );push (new (as usize ).into (),into (),None ,println! ("mapping memory-mapped registers" );for pair in MMIO {push (new (0 .into (),0 + (*pair).1 ).into (),None ,
用户
在第三章中,每个应用链接脚本中的起始地址被要求是不同的,这样它们的代码和数据存放的位置才不会产生冲突。但这是一种对于应用开发者很不方便的设计。现在,借助地址空间的抽象,我们终于可以让所有应用程序都使用同样的起始地址,这也意味着所有应用可以使用同一个链接脚本了
在上一章,我们实际上是这样构建的:
1 2 3 elf: $(APPS)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import os0x80400000 0x20000 'src/linker.ld' 0 'src/bin' )for app in apps:'.' )]with open (linker, 'r' ) as f:for line in f.readlines():hex (base_address), hex (base_address+step*app_id))with open (linker, 'w+' ) as f:'cargo build --bin %s --release' % app)print ('[build.py] application %s start with address %s' %(app, hex (base_address+step*app_id)))with open (linker, 'w+' ) as f:1
实际上等于手动 在文件链接前,改变linker.ld的 base_address
现在我们有虚拟内存的机制,可以丢弃这个过程,简单地编译就行( .cargo/config.toml 已经使用了 linker.ld 来编译)
1 2 elf: $(APPS)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 pub fn from_elf (elf_data: &[u8 ]) -> (Self , usize , usize ) {let mut memory_set = Self ::new_bare ();map_trampoline ();let elf = xmas_elf::ElfFile::new (elf_data).unwrap ();let elf_header = elf.header;let magic = elf_header.pt1.magic;assert_eq! (magic, [0x7f , 0x45 , 0x4c , 0x46 ], "invalid elf!" );let ph_count = elf_header.pt2.ph_count ();let mut max_end_vpn = VirtPageNum (0 );for i in 0 ..ph_count {let ph = elf.program_header (i).unwrap ();if ph.get_type ().unwrap () == xmas_elf::program::Type::Load {let start_va : VirtAddr = (ph.virtual_addr () as usize ).into ();let end_va : VirtAddr = ((ph.virtual_addr () + ph.mem_size ()) as usize ).into ();let mut map_perm = MapPermission::U;let ph_flags = ph.flags ();if ph_flags.is_read () {if ph_flags.is_write () {if ph_flags.is_execute () {let map_area = MapArea::new (start_va, end_va, MapType::Framed, map_perm);get_end ();push (Some (&elf.input[ph.offset () as usize ..(ph.offset () + ph.file_size ()) as usize ]),let max_end_va : VirtAddr = max_end_vpn.into ();let mut user_stack_bottom : usize = max_end_va.into ();let user_stack_top = user_stack_bottom + USER_STACK_SIZE;push (new (into (),into (),None ,push (new (into (),into (),None ,push (new (into (),into (),None ,entry_point () as usize ,
最终,用户应用和内核被放在同一个文件中。我们会调用loader.rs中的 get_app_data 得到指定 app 的 elf 文件,在from_elf函数中,解析该 elf 文件、得到逻辑段并设置好用户的地址空间。返回应用地址空间 memory_set ,也同时返回用户栈虚拟地址 user_stack_top 以及从解析 ELF 得到的该应用入口点地址,它们将被我们用来创建应用的任务控制块。
调整空间 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #[allow(unused)] pub fn shrink_to (&mut self , start: VirtAddr, new_end: VirtAddr) -> bool {if let Some (area) = self iter_mut ()find (|area| area.vpn_range.get_start () == start.floor ())shrink_to (&mut self .page_table, new_end.ceil ());true else {false #[allow(unused)] pub fn append_to (&mut self , start: VirtAddr, new_end: VirtAddr) -> bool {if let Some (area) = self iter_mut ()find (|area| area.vpn_range.get_start () == start.floor ())append_to (&mut self .page_table, new_end.ceil ());true else {false
分时多任务支持不同地址空间 Trap 我们关注改过的代码。
拓展上下文 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #[repr(C)] pub struct TrapContext {pub x: [usize ; 32 ],pub sstatus: Sstatus,pub sepc: usize ,pub kernel_satp: usize ,pub kernel_sp: usize ,pub trap_handler: usize ,
Rust 默认的结构体布局是优化过的,这可能会和 C 语言的结构体布局不同,#[repr(C)] 强制 Rust 使用与 C 语言相同的布局规则。
在多出的三个字段中:
kernel_satp 表示内核地址空间的 token ,即内核页表的起始物理地址;kernel_sp 表示当前应用在内核地址空间中的内核栈栈顶的虚拟地址;trap_handler 表示内核中 trap handler 入口点的虚拟地址。
他们在初始化之后就不会改变。
修改返回地址 思考一个问题,我们的trap_handler函数并没有放在TRAMPOLINE中,然而__alltraps需要找到trap_handler的正确地址。所以我们需要提前将trap_handler放入TrapContext,方便我们跳转。
因为在内存布局中,这条 .text.trampoline 段中的跳转指令和 trap_handler 都在代码段之内,汇编器(Assembler)和链接器(Linker)会根据 linker-qemu/k210.ld 的地址布局描述,设定跳转指令的地址,并计算二者地址偏移量,让跳转指令的实际效果为当前 pc 自增这个偏移量。但实际上由于我们设计的缘故,这条跳转指令在被执行的时候,它的虚拟地址被操作系统内核设置在地址空间中的最高页面之内,所以加上这个偏移量并不能正确的得到 trap_handler 的入口地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 __alltraps: sp , sscratch, sp 1 *8 (sp )3 *8 (sp ).set n, 5 .rept 27 .set n, n+1 .endr t0 , sstatust1 , sepct0 , 32 *8 (sp )t1 , 33 *8 (sp )t2 , sscratcht2 , 2 *8 (sp )t0 , 34 *8 (sp )t1 , 36 *8 (sp )sp , 35 *8 (sp )t0 jr t1
虽然进行该过程时,处于内核态,但我们需要利用用户态的地址空间。与前面的实现(将TrapContext放在内核栈)不同,这里将其放在应用地址空间 中(见前面用户空间的布局图)。所以我们会在用户空间下,保存上下文到TrapContext后,从该TrapContext中,取出初始化时就设置好的kernel_satp trap_handler kernel_sp,按顺序:移动栈指针指向内核栈、切换到内核地址空间、使用jr跳转到trap_handler
1 2 3 4 5 6 7 8 9 10 11 #[no_mangle] pub fn trap_handler () -> ! {set_kernel_trap_entry ();let cx = current_trap_cx ();let scause = scause::read ();let stval = stval::read ();match scause.cause () {trap_return ();
进入该函数后,我们先需要处理 S态 Trap。set_kernel_trap_entry会将stvec设置为处理S态Trap函数的地址,目前该函数是直接 panic。接着处理流程和之前一样。
最后我们会进入trap_return,完成回到用户空间的准备工作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #[no_mangle] pub fn trap_return () -> ! {set_user_trap_entry ();let trap_cx_ptr = TRAP_CONTEXT;let user_satp = current_user_token ();extern "C" {fn __alltraps ();fn __restore ();let restore_va = __restore as usize - __alltraps as usize + TRAMPOLINE;unsafe {"fence.i" ,"jr {restore_va}" ,in (reg) restore_va,in ("a0" ) trap_cx_ptr,in ("a1" ) user_satp,options (noreturn)panic! ("Unreachable in back_to_user!" );
首先设置了stvec为TRAMPOLINE的起始位置
注:我们把 stvec 设置为内核和应用地址空间共享的跳板页面的起始地址 TRAMPOLINE 而不是编译器在链接时看到的 __alltraps 的地址。这是因为启用分页模式之后,内核只能通过跳板页面上的虚拟地址来实际取得 __alltraps 和 __restore 的汇编代码。
现在我们的__restore需要:用户空间中TrapContext的虚拟地址、用户的页表(将要执行的应用)。在这里准备好之后,就可以使用restore_ra跳转过去了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 __restore: a1 a0 sp , a0 t0 , 32 *8 (sp )t1 , 33 *8 (sp )t0 t1 1 *8 (sp )3 *8 (sp ).set n, 5 .rept 27 .set n, n+1 .endr sp , 2 *8 (sp )
基本上和__alltraps相反:我们先切换地址空间到应用,通过得到的TrapContext的虚拟地址,恢复上下文,最终回到用户空间。
Task 接着我们看:多任务怎么支持地址空间。
拓展任务管理结构 1 2 3 4 5 6 7 8 9 10 11 12 pub struct TaskControlBlock {pub task_status: TaskStatus,pub task_cx: TaskContext,pub memory_set: MemorySet,pub trap_cx_ppn: PhysPageNum,#[allow(unused)] pub base_size: usize ,pub heap_bottom: usize ,pub program_brk: usize ,
除了应用的地址空间 memory_set 之外,还有位于应用地址空间次高页的 Trap 上下文被实际存放在物理页帧的物理页号 trap_cx_ppn ,它能够方便我们对于 Trap 上下文进行访问。此外, base_size 统计了应用数据的大小,也就是在应用地址空间中从 开始到用户栈结束一共包含多少字节。
trap_cx_ppn并非必要,但加了确实可以更方便。最后3个,用于支持应用内的动态分配(sbrk)
任务管理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 impl TaskControlBlock {pub fn get_trap_cx (&self ) -> &'static mut TrapContext {self .trap_cx_ppn.get_mut ()pub fn get_user_token (&self ) -> usize {self .memory_set.token ()pub fn new (elf_data: &[u8 ], app_id: usize ) -> Self {let (memory_set, user_sp, entry_point) = MemorySet::from_elf (elf_data);let trap_cx_ppn = memory_settranslate (VirtAddr::from (TRAP_CONTEXT).into ())unwrap ()ppn ();let task_status = TaskStatus::Ready;let (kernel_stack_bottom, kernel_stack_top) = kernel_stack_position (app_id);exclusive_access ().insert_framed_area (into (),into (),let task_control_block = Self {goto_trap_return (kernel_stack_top),let trap_cx = task_control_block.get_trap_cx ();app_init_context (exclusive_access ().token (),as usize ,
新建一个任务时,我们先用from_elf解析 elf 文件,得到映射完成 的用户地址空间、用户栈、进入地址。接着通过 app_id计算出偏移量,找到应用对应的内核栈地址,并添加映射。构造好用户的上下文:TrapContext和TaskContext。和之前类似,我们会将TaskContext设置为返回用户态前的入口,这里是trap_return。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 pub fn change_program_brk (&mut self , size: i32 ) -> Option <usize > {let old_break = self .program_brk;let new_brk = self .program_brk as isize + size as isize ;if new_brk < self .heap_bottom as isize {return None ;let result = if size < 0 {self .memory_setshrink_to (VirtAddr (self .heap_bottom), VirtAddr (new_brk as usize ))else {self .memory_setappend_to (VirtAddr (self .heap_bottom), VirtAddr (new_brk as usize ))if result {self .program_brk = new_brk as usize ;Some (old_break)else {None
向外提供了调整程序 break 的方法
剩下的懒得打了。。。。
从一次启动来看 前面是从开发的角度看的,现在我们试着从程序运行的顺序来看整个系统和过程:
文件编译:注意应用程序不再是bin而是elf。通过build.rs生成了link_app.S。每个应用都有一样的基址(应用认为的)。将内核和应用程序都放在一起。
qemu引导,进入rust_main
mm::init
init_heap:设置堆空间,开启内核级的动态分配init_frame_allocator:初始化可管理的物理内存使用new_kernel新建内核地址空间(其中会完成内核部分的映射),并开启硬件支持的 SV39 页表转换。
trap::init
将stvec设置为内核 trap 处理入口(目前等于禁止内核 trap)
trap::enable_timer_interrupt + timer::set_next_trigger:开启时钟中断开始第一个任务
task::run_first_task
初始化TaskManager:加载应用 elf 文件,完成应用的地址空间的映射,构建应用的TaskControlBlock
切换至第一个应用的TaskContext,我们已经提前布置过,会到达trap_return函数,以及指向该应用的内核栈。(由于都是在内核地址空间下的操作,不需要修改satp)
trap_return:设置stvec为__alltraps,根据TaskContext的内容,得到用户的页表位置、TrapContext(在用户地址空间中)的位置,使用__restore__restore:切换到用户地址空间,找到TrapContext并恢复上下文,初次会到达应用的entry_point并得到用户栈的位置(初始化时设置好的),接着就开始执行第一个用户应用
发生中断/异常:
系统调用:依次经过__alltraps->trap_handler->系统调用函数->trap_return->__restore
需要切换任务:同理,只不过需要切换应用的内核栈
完成所有 task 并退出