#os #proj #rust
背景知识 协程 我对进程和线程的概念有一定了解,但没了解过协程的概念。协程可以看作是用户态的线程,由调用方去控制。
找到较好的参考文章:协程简介
有栈与无栈协程
协程运行在线程上,本质是单线程。在异步的场景下(比如大量的 IO),协程通过主动让出线程资源,来达到异步。这就是为什么叫做“协程”,有别与线程的抢占式执行。其实函数调用就是一种特殊的协程,只不过这个协程在最后才切换出去。
具体实现
时间不是很够了,不可能深入所有代码,只能大概捋顺思路
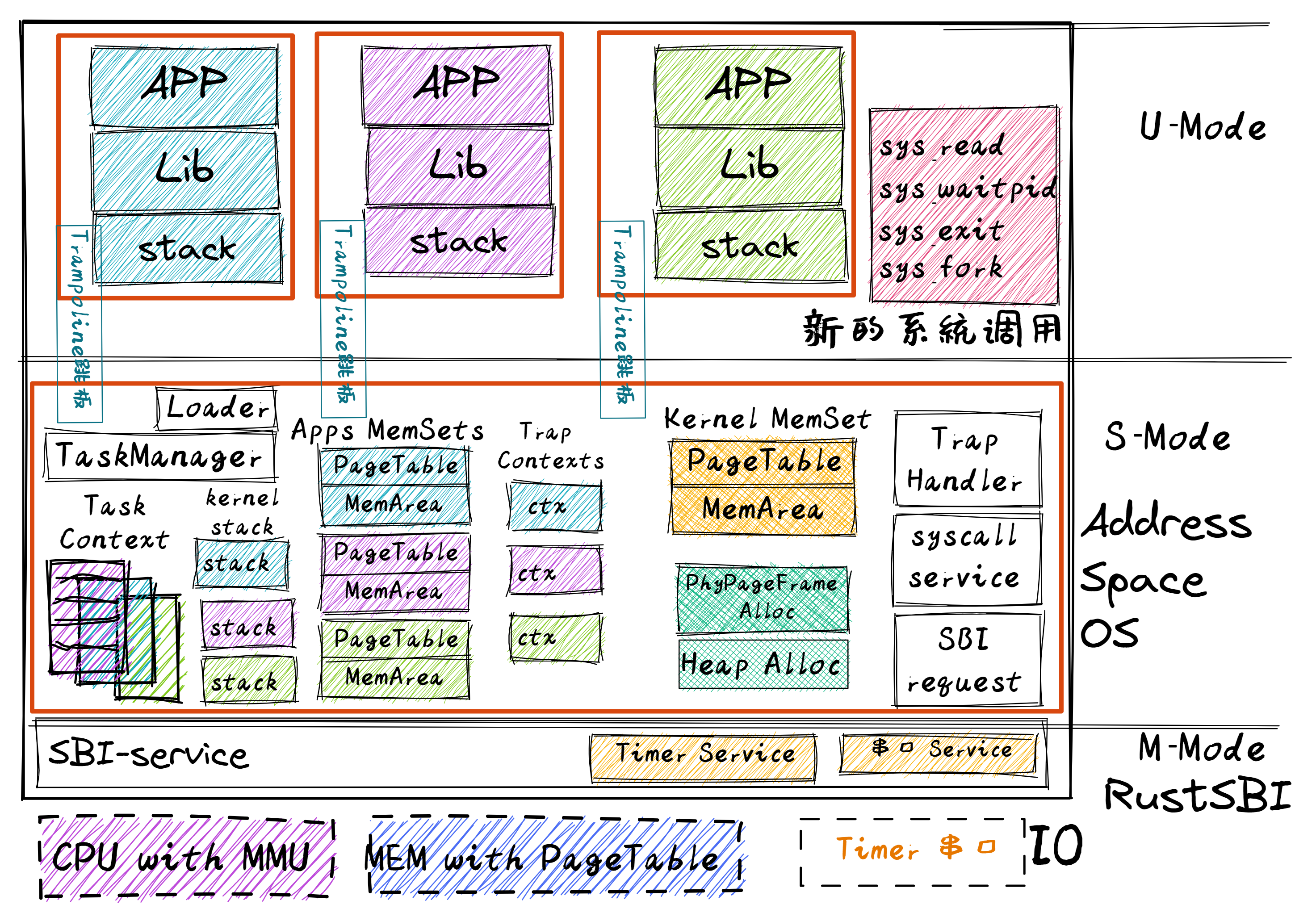
进程管理基础设施 我们的目标是可以通过 fork 和 exec 来管理进程,完成了以下基础:
基于应用名的链接和加载 看脚本和汇编代码,还有loader.rs
进程标识符 1 pub struct PidHandle (pub usize );
其设计和FrameTracker很像,我们同样有:
1 2 3 4 struct PidAllocator {usize ,Vec <usize >,
用来管理 PID 的分配回收。
之前我们用 app_id 来管理各个应用在内核空间的内核栈,现在可以看成将 app_id 变成 PID。
1 2 3 pub struct KernelStack {usize ,
添加 KernelStack 方便管理对应内核栈,同时该结构提供了获取栈顶和入栈的方法。在创建一个内核栈时,会顺便完成虚实的映射。在内核栈生命周期结束后,会自动使用drop方法,通过移除逻辑段方法 remove_area_with_start_vpn 来释放空间
进程控制块 PCB 用于管理一个进程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 pub struct TaskControlBlock {pub pid: PidHandle,pub kernel_stack: KernelStack,pub struct TaskControlBlockInner {pub trap_cx_ppn: PhysPageNum,pub base_size: usize ,pub task_cx: TaskContext,pub task_status: TaskStatus,pub memory_set: MemorySet,pub parent: Option <Weak<TaskControlBlock>>,pub children: Vec <Arc<TaskControlBlock>>,pub exit_code: i32 ,
parent 指向当前进程的父进程(如果存在的话)。注意我们使用 Weak 而非 Arc 来包裹另一个任务控制块,因此这个智能指针将不会影响父进程的引用计数。children 则将当前进程的所有子进程的任务控制块以 Arc 智能指针的形式保存在一个向量中,这样才能够更方便的找到它们。trap_cx_ppn 指出了应用地址空间中的 Trap 上下文(详见第四章)被放在的物理页帧的物理页号。base_size 的含义是:应用数据仅有可能出现在应用地址空间低于 base_size 字节的区域中。借助它我们可以清楚的知道应用有多少数据驻留在内存中。task_cx 将暂停的任务的任务上下文保存在任务控制块中。
我们还给 PCB 实现以下方法来直接管理进程:
new(创建进程,只用于 initproc)
exec 加载并执行另一个可执行文件
fork 复制一个几乎相同的子进程
任务管理器 1 2 3 pub struct TaskManager {
维护一个双端队列,负责取出/放入任务(PCB)。使用引用来减少数据移动开销。
处理器管理 为了方便多核运行的环境,抽象出处理器这个结构
1 2 3 4 pub struct Processor {Option <Arc<TaskControlBlock>>,
idle_task_cx 表示当前处理器上的 idle 控制流的任务上下文。
其提供了查看/换入/换出任务的方法。
进程切换 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 pub fn run_tasks () {loop {let mut processor = PROCESSOR.exclusive_access ();if let Some (task) = fetch_task () {let idle_task_cx_ptr = processor.get_idle_task_cx_ptr ();let mut task_inner = task.inner_exclusive_access ();let next_task_cx_ptr = &task_inner.task_cx as *const TaskContext;drop (task_inner);Some (task);drop (processor);unsafe {
一个比较有意思的设计是:这里在切换时,会先切换到 idle 控制流,再从 idle 控制流切换到下一个任务。这样设计的目的是使的进程的切换对每一个进程的内核栈都是透明的:
使得换入/换出进程和调度执行流在内核层各自执行在不同的内核栈上,分别是进程自身的内核栈和内核初始化时使用的启动栈。这样的话,调度相关的数据不会出现在进程内核栈上,也使得调度机制对于换出进程的Trap执行流是不可见的,它在决定换出的时候只需调用schedule而无需操心调度的事情。从而各执行流的分工更加明确了,虽然带来了更大的开销。
1 2 3 4 5 6 7 8 9 10 11 pub fn schedule (switched_task_cx_ptr: *mut TaskContext) {let mut processor = PROCESSOR.exclusive_access ();let idle_task_cx_ptr = processor.get_idle_task_cx_ptr ();drop (processor);unsafe {
所以进程切换的流程如下:
时间耗尽/yield,陷入内核态
内核调用 schedule,切换到 idle 流
idle 流从上次 switch 后的地方继续执行:即再一次 run_task
idle 流切换到下一个进程,下一个进程会从内核态恢复到用户态继续执行。
进程管理机制 创建初始进程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 pub fn new (elf_data: &[u8 ]) -> Self {let (memory_set, user_sp, entry_point) = MemorySet::from_elf (elf_data);let trap_cx_ppn = memory_settranslate (VirtAddr::from (TRAP_CONTEXT).into ())unwrap ()ppn ();let pid_handle = pid_alloc ();let kernel_stack = KernelStack::new (&pid_handle);let kernel_stack_top = kernel_stack.get_top ();let task_control_block = Self {unsafe { UPSafeCell::new (TaskControlBlockInner {goto_trap_return (kernel_stack_top),None ,Vec ::new (),0 ,let trap_cx = task_control_block.inner_exclusive_access ().get_trap_cx ();app_init_context (exclusive_access ().token (),as usize ,
解析 initproc 的初始文件,创建用户地址空间
从地址空间中得到存放 TrapContext 的地方
分配 PID,并根据 PID 获得对应的内核栈、及其栈顶的位置
初始化 PCB
初始化用户空间的 TrapContext(设置好入口等)
进程调度 前一部分已经讲了大概流程,再看看 schedule 前的接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 pub fn suspend_current_and_run_next () {let task = take_current_task ().unwrap ();let mut task_inner = task.inner_exclusive_access ();let task_cx_ptr = &mut task_inner.task_cx as *mut TaskContext;drop (task_inner);add_task (task);schedule (task_cx_ptr);
注意这里是要取出 PCB,放回等待队列中。
进程生成 除了 initproc 是内核手动生成的,其余的进程都是通过 fork or exec 产生的。
先看 fork 的实现:(在此之前,给 MemorySet 新增了根据已有地址空间创建新的地址空间的方法from_existed_user)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 impl TaskControlBlock {pub fn fork (self : &Arc<TaskControlBlock>) -> Arc<TaskControlBlock> {let mut parent_inner = self .inner_exclusive_access ();let memory_set = MemorySet::from_existed_user (let trap_cx_ppn = memory_settranslate (VirtAddr::from (TRAP_CONTEXT).into ())unwrap ()ppn ();let pid_handle = pid_alloc ();let kernel_stack = KernelStack::new (&pid_handle);let kernel_stack_top = kernel_stack.get_top ();let task_control_block = Arc::new (TaskControlBlock {unsafe { UPSafeCell::new (TaskControlBlockInner {goto_trap_return (kernel_stack_top),Some (Arc::downgrade (self )),Vec ::new (),0 ,push (task_control_block.clone ());let trap_cx = task_control_block.inner_exclusive_access ().get_trap_cx ();
fork 的方法类似 new。注意我们复制地址空间时,顺便会把TrapContext给复制了(记得上章时,我们把TrapContext放在了用户地址空间的固定虚拟地址处),这样我们从内核态返回到这个新的进程的用户态时,会从调用 fork 后开始执行且状态和调用瞬间一样,十分巧妙。
如何让 parent 和 child 的 fork 返回值不一样?
1 2 3 4 5 6 7 8 9 10 11 12 13 pub fn sys_fork () -> isize {let current_task = current_task ().unwrap ();let new_task = current_task.fork();let new_pid = new_task.pid.0 ;let trap_cx = new_task.inner_exclusive_access ().get_trap_cx ();10 ] = 0 ; add_task (new_task);as isize
我们需要手动设置系统调用的返回值,通过修改子进程的 TrapContext 。
接着看 exec 的实现:
exec 系统调用使得一个进程能够加载一个新应用的 ELF 可执行文件中的代码和数据替换原有的应用地址空间中的内容,并开始执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 impl TaskControlBlock {pub fn exec (&self , elf_data: &[u8 ]) {let (memory_set, user_sp, entry_point) = MemorySet::from_elf (elf_data);let trap_cx_ppn = memory_settranslate (VirtAddr::from (TRAP_CONTEXT).into ())unwrap ()ppn ();let mut inner = self .inner_exclusive_access ();let trap_cx = inner.get_trap_cx ();app_init_context (exclusive_access ().token (),self .kernel_stack.get_top (),as usize ,
我们直接从 elf 文件构建出一个新的地址空间。原地址空间的生命周期结束,根据其类似 RAII 的特性,所分配的物理页都会自动释放。同时需要修改 TrapContext,初始化(类似 new)。无需修改 TaskContext,因为本质上还是同一个进程。
1 2 3 4 5 6 7 8 9 10 11 12 13 pub fn sys_exec (path: *const u8 ) -> isize {let token = current_user_token ();let path = translated_str (token, path);if let Some (data) = get_app_data_by_name (path.as_str ()) {let task = current_task ().unwrap ();exec (data);0 else {1
translated_str:我们的目标程序路径的字符串是在用户空间的,要在内核态读取需要经过用户页表的地址转换。
可以看到,我们的系统调用是有可能改变 TrapContext 的位置的,原来的 trap_handler 没有注意这个,我们需要在 syscall 函数后重新获取 TrapContext
进程退出 sys_exit / 程序异常都会调用 exit_current_and_run_next
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 pub fn exit_current_and_run_next (exit_code: i32 ) {let task = take_current_task ().unwrap ();let mut inner = task.inner_exclusive_access ();let mut initproc_inner = INITPROC.inner_exclusive_access ();for child in inner.children.iter () {inner_exclusive_access ().parent = Some (Arc::downgrade (&INITPROC));push (child.clone ());clear ();recycle_data_pages ();drop (inner);drop (task);let mut _unused = TaskContext::zero_init ();schedule (&mut _unused as *mut _);
取出当前进程并设置为僵尸进程
我们将进程控制块中的状态修改为 TaskStatus::Zombie 即僵尸进程,这样它后续才能被父进程在 waitpid 系统调用的时候回收;
同时会将当前进程的全部子进程挂在 initproc 下
提前回收该应用的地址空间
无需提供当前的 TaskContext 的地址了:因为我们不会再回来
子进程的完全回收是通过父进程实现的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 pub fn sys_waitpid (pid: isize , exit_code_ptr: *mut i32 ) -> isize {let task = current_task ().unwrap ();let mut inner = task.inner_exclusive_access ();if inner.childreniter ()find (|p| {pid == -1 || pid as usize == p.getpid ()})is_none () {return -1 ;let pair = inner.childreniter ()enumerate ()find (|(_, p)| {inner_exclusive_access ().is_zombie () && (pid == -1 || pid as usize == p.getpid ())if let Some ((idx, _)) = pair {let child = inner.children.remove (idx);assert_eq! (Arc::strong_count (&child), 1 );let found_pid = child.getpid ();let exit_code = child.inner_exclusive_access ().exit_code;translated_refmut (inner.memory_set.token (), exit_code_ptr) = exit_code;as isize else {2
第 29 行确认这是对于该子进程控制块的唯一一次强引用,即它不会出现在某个进程的子进程向量中,更不会出现在处理器监控器或者任务管理器中。当它所在的代码块结束,这次引用变量的生命周期结束,将导致该子进程进程控制块的引用计数变为 0 ,彻底回收掉它占用的所有资源,包括:内核栈和它的 PID 还有它的应用地址空间存放页表的那些物理页帧等等。
第 34 行写入到当前进程的应用地址空间中。由于应用传递给内核的仅仅是一个指向应用地址空间中保存子进程返回值的内存区域的指针,我们还需要在 translated_refmut 中手动查页表找到应该写入到物理内存中的哪个位置,这样才能把子进程的退出码 exit_code 返回给父进程。其实现可以在 os/src/mm/page_table.rs 中找到,比较简单,在这里不再赘述。