#os #rust #proj
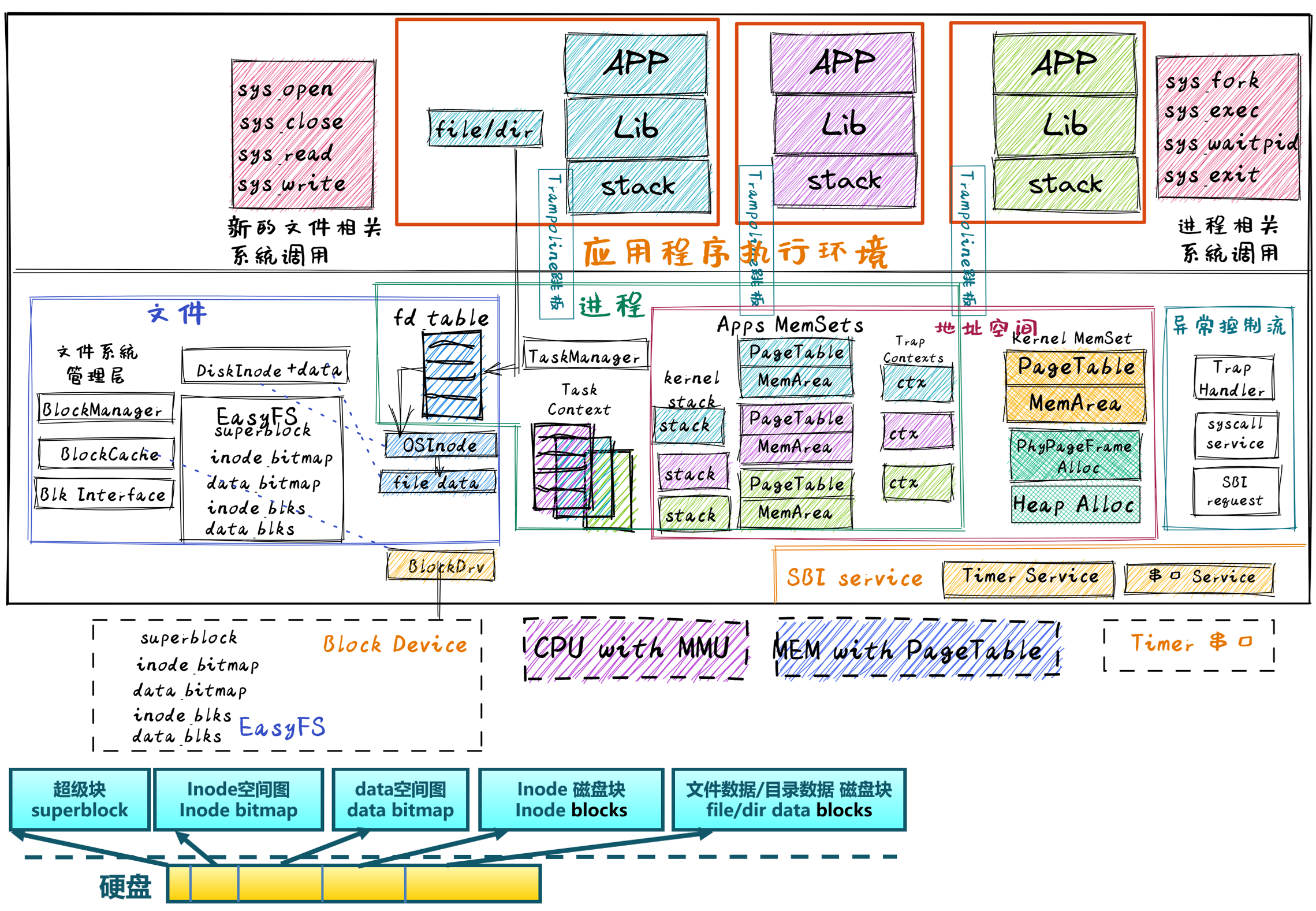
背景知识 在下面的描述中,“文件”有可能指的是常规文件、目录,也可能是之前提到的若干种进程可以读写的 标准输出、标准输入、管道等I/O 资源
文件
同一个文件系统中如果两个文件(目录也是文件)具有相同的inode号码,那么就称它们是“硬链接 ”关系。这样links的值其实是一个文件的不同文件名的数量。
实际上目录也可以看作一种文件,它也有属于自己的底层编号,它的内容中保存着若干 目录项 (Dirent, Directory Entry) ,可以看成一组映射,根据它下面的文件名或子目录名能够查到文件和子目录在文件系统中的底层编号,即 Inode 编号。但是与常规文件不同的是,用户无法 直接 修改目录的内容,只能通过创建/删除它下面的文件或子目录才能间接做到这一点。
文件系统
持久存储设备仅支持以扇区(或块)为单位的随机读写,这和上面介绍的通过路径即可索引到文件并以字节流进行读写的用户视角有很大的不同。负责中间转换的便是 文件系统 (File System) 。具体而言,文件系统负责将逻辑上的目录树结构(包括其中每个文件或目录的数据和其他信息)映射到持久存储设备上,决定设备上的每个扇区应存储哪些内容。反过来,文件系统也可以从持久存储设备还原出逻辑上的目录树结构。
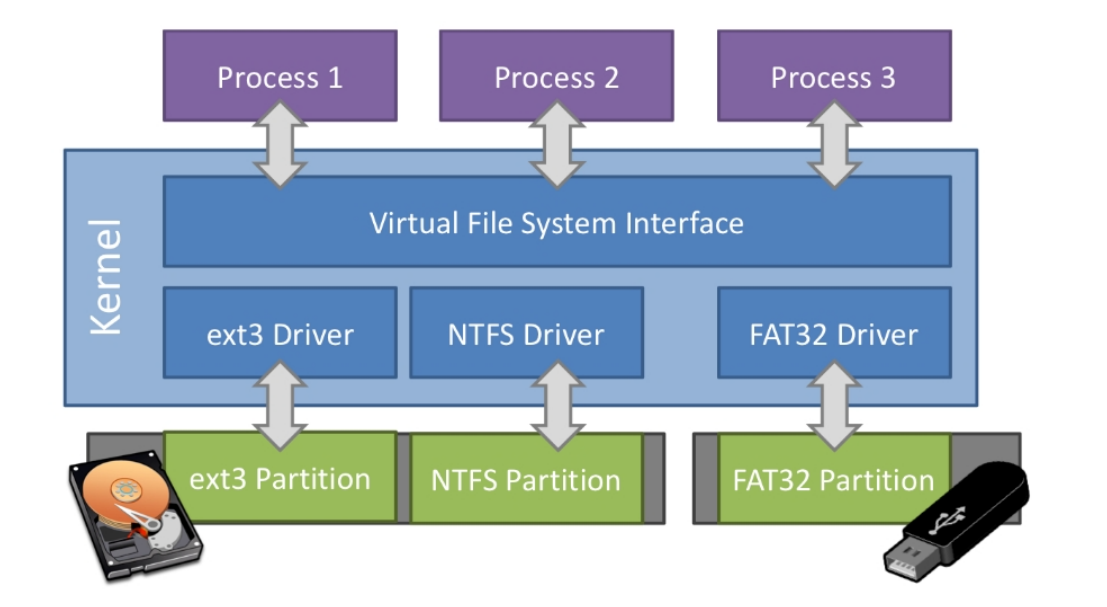
文件系统有很多种不同的实现,每一种都能将同一个逻辑上目录树结构转化为一个不同的持久存储设备上的扇区布局。最著名的文件系统有 Windows 上的 FAT/NTFS 和 Linux 上的 Ext3/Ext4/Btrfs 等。
在一个计算机系统中,可以同时包含多个持久存储设备,它们上面的数据可能是以不同文件系统格式存储的。为了能够对它们进行统一管理,在内核中有一层 虚拟文件系统 (VFS, Virtual File System) ,它规定了逻辑上目录树结构的通用格式及相关操作的抽象接口,只要不同的底层文件系统均实现虚拟文件系统要求的那些抽象接口,再加上 挂载 (Mount) 等方式,这些持久存储设备上的不同文件系统便可以用一个统一的逻辑目录树结构一并进行管理。
块和扇区是两个不同的概念。 扇区 (Sector) 是块设备随机读写的数据单位,通常每个扇区为 512 字节。而块是文件系统存储文件时的数据单位,每个块的大小等同于一个或多个扇区。之前提到过 Linux 的Ext4文件系统的单个块大小默认为 4096 字节。在我们的 easy-fs 实现中一个块和一个扇区同为 512 字节,因此在后面的讲解中我们不再区分扇区和块的概念。
具体实现 跳过用户态的 easy-fs,直接看内核中的 easy-fs 的多层模型。
块设备驱动层 我们先假设使用的硬件是qemu:
1 2 3 4 5 6 QEMU_ARGS := -machine virt \$(BOOTLOADER) \$(KERNEL_BIN) ,addr=$(KERNEL_ENTRY_PA) \$(FS_IMG) ,if=none,format=raw,id=x0 \
可以看到我们添加了虚拟硬盘(包含应用的文件系统镜像),并将其作为Virtio总线中的一个块设备接入系统,使用 MMIO (Memory-Mapped IO) 控制,在总线的编号为0
我们需要在初始化内核地址空间时添加 MMIO 地址空间的页表映射。
1 2 3 4 5 6 7 8 9 10 11 12 pub struct VirtIOBlock (UPSafeCell<VirtIOBlk<'static , VirtioHal>>);impl VirtIOBlock {#[allow(unused)] pub fn new () -> Self {unsafe {Self (UPSafeCell::new (new (&mut *(VIRTIO0 as *mut VirtIOHeader)).unwrap (),
这是 VirtIOBlk 的包装,提供了互斥访问。'static代表了其生命周期等于程序运行的生命周期。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 impl BlockDevice for VirtIOBlock {fn read_block (&self , block_id: usize , buf: &mut [u8 ]) {self .0 exclusive_access ()read_block (block_id, buf)expect ("Error when reading VirtIOBlk" );fn write_block (&self , block_id: usize , buf: &[u8 ]) {self .0 exclusive_access ()write_block (block_id, buf)expect ("Error when writing VirtIOBlk" );
这个是我们对 VirtIOBlk 接口的包装。我们还需要为该设备实现 VirtQueue 的物理内存的分配回收,但这里省略。
总而言之,我们现在为上层的文件系统提供了接口!
文件系统层 块设备接口层 1 2 3 4 5 6 pub trait BlockDevice : Send + Sync + Any {fn read_block (&self , block_id: usize , buf: &mut [u8 ]);fn write_block (&self , block_id: usize , buf: &[u8 ]);
直接使用硬件提供的接口即可。
块缓存层 1 2 3 4 5 6 7 8 9 10 pub struct BlockCache {u8 ; BLOCK_SZ],usize ,dyn BlockDevice>,bool ,
每个 cache 负责缓存一个数据块。dyn表示该类型只有在运行时才会被决定(因为我们并不知道使用的是 k210 还是 qemu,Arc得到一个块设备的引用。
1 2 3 pub struct BlockCacheManager {usize , Arc<Mutex<BlockCache>>)>,
负责管理多个 cache:写回/读取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 pub fn get_block_cache (mut self ,usize ,dyn BlockDevice>,-> Arc<Mutex<BlockCache>> {if let Some (pair) = self .queue.iter ().find (|pair| pair.0 == block_id) {clone (&pair.1 )else {if self .queue.len () == BLOCK_CACHE_SIZE {if let Some ((idx, _)) = self iter ()enumerate ()find (|(_, pair)| Arc::strong_count (&pair.1 ) == 1 )self .queue.drain (idx..=idx);else {panic! ("Run out of BlockCache!" );let block_cache = Arc::new (Mutex::new (BlockCache::new (clone (&block_device),self .queue.push_back ((block_id, Arc::clone (&block_cache)));
现在我们可以通过 Block id 来获取相应的缓存块。下一层就是以块为单位进行操作。
磁盘数据结构层
超级块 1 2 3 4 5 6 7 8 9 #[repr(C)] pub struct SuperBlock {u32 ,pub total_blocks: u32 ,pub inode_bitmap_blocks: u32 ,pub inode_area_blocks: u32 ,pub data_bitmap_blocks: u32 ,pub data_area_blocks: u32 ,
所以文件系统的开头就是魔数,可以通过检查魔数来判断该文件是否是文件系统。
位图 1 2 3 4 pub struct Bitmap {usize ,usize ,
同时位图还提供了根据 block id 修改位图的方法(一些 bit 操作)
磁盘索引节点 每个文件/目录都可以用 DiskInode 来索引(一个 DiskInode 对应一个文件/目录)
1 2 3 4 5 6 7 8 [repr (C)]pub struct DiskInode {pub size: u32 ,pub direct: [u32 ; INODE_DIRECT_COUNT],pub indirect1: u32 ,pub indirect2: u32 ,
块的编号可以用 u32 来进行存储,每个 DiskInode 都会保存直接索引 & 间接索引。关于怎么用间接索引等,看源码就行。
数据块 分为单纯的数据块和目录的块。目录块由 DirEntry 构成:
1 2 3 4 pub struct DirEntry {u8 ; NAME_LENGTH_LIMIT + 1 ],u32 ,
即我们可以用名字(字符串)来获取对应的子目录/文件的索引节点
磁盘块管理器层 1 2 3 4 5 6 7 8 9 10 pub struct EasyFileSystem {pub block_device: Arc<dyn BlockDevice>,pub inode_bitmap: Bitmap,pub data_bitmap: Bitmap,u32 ,u32 ,
EFS 可以控制磁盘数据结构平面。其通过 block device 以及 block 和 bitmap 数来创造create一个新的文件系统(空间清0、通过上述参数初始化超级块、创建根目录)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 impl EasyFileSystem {pub fn open (block_device: Arc<dyn BlockDevice>) -> Arc<Mutex<Self >> {get_block_cache (0 , Arc::clone (&block_device))lock ()read (0 , |super_block: &SuperBlock| {assert! (super_block.is_valid (), "Error loading EFS!" );let inode_total_blocks =let efs = Self {new (1 ,as usize new (1 + inode_total_blocks) as usize ,as usize ,1 + super_block.inode_bitmap_blocks,1 + inode_total_blocks + super_block.data_bitmap_blocks,new (Mutex::new (efs))
打开文件系统。本质是:读取块设备(这里看成是文件系统镜像)中的超级块,便可以将该文件系统的布局放在内存中,由 EFS 管理
索引节点层
DiskInode 放在磁盘块中比较固定的位置,而 Inode 是放在内存中的记录文件索引节点信息的数据结构。
1 2 3 4 5 6 7 8 pub struct Inode {usize ,usize ,dyn BlockDevice>,
文件系统的使用者会用 Inode 来管理文件/目录。需要 fs 和 block_device 是因为 Inode 本质上需要控制 EFS 以及传递指针给下层的函数。
内核索引节点层 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 pub struct OSInode {bool ,bool ,pub struct OSInodeInner {usize ,impl OSInode {pub fn new (bool ,bool ,-> Self {Self {new (OSInodeInner {0 ,
文件描述符层
一个进程可以访问的多个文件,所以在操作系统中需要有一个管理进程访问的多个文件的结构,这就是 文件描述符表 (File Descriptor Table) ,其中的每个 文件描述符 (File Descriptor) 代表了一个特定读写属性的I/O资源。
OSInode 也属于这个范畴,所以需要进一步将 OSInode 封装为 fd。每个进程可能会同时访问多个文件,会在自身的结构中维护文件描述符的表:
1 2 3 4 5 6 7 8 9 10 11 pub struct TaskControlBlockInner {pub trap_cx_ppn: PhysPageNum,pub base_size: usize ,pub task_cx_ptr: usize ,pub task_status: TaskStatus,pub memory_set: MemorySet,pub parent: Option <Weak<TaskControlBlock>>,pub children: Vec <Arc<TaskControlBlock>>,pub exit_code: i32 ,pub fd_table: Vec <Option <Arc<dyn File + Send + Sync >>>,
同时继续向上提供抽象(所有的 fd 都需要这个抽象):
1 2 3 4 5 6 7 8 9 10 pub trait File : Send + Sync {fn readable (&self ) -> bool ;fn writable (&self ) -> bool ;fn read (&self , buf: UserBuffer) -> usize ;fn write (&self , buf: UserBuffer) -> usize ;
至此,我们就完成了文件系统自底向上的浏览。
应用访问文件流程
1 2 3 lazy_static! {pub static ref BLOCK_DEVICE: Arc<dyn BlockDevice> = Arc::new (BlockDeviceImpl::new ());
1 2 3 4 5 6 lazy_static! {pub static ref ROOT_INODE: Arc<Inode> = {let efs = EasyFileSystem::open (BLOCK_DEVICE.clone ());new (EasyFileSystem::root_inode (&efs))
获取根目录的 Inode
打开文件:open_file根据文件名以及标志,在根目录中寻找/创建文件,返回包裹过的 OSInode,在 sys_open中,会放入 fd 表中
读写文件:使用 fd 的抽象(即 File 的 trait)来读写,向上抽象成 sys_read/sys_write。
加载文件:sys_exec只需要将文件读出来并交给 task 的exec函数即可,无需 loader 加载
关闭文件:sys_close会将指定 fd 对应的 OSInode引用 丢弃,从而减少计数